I was recently doing some System Center work on a customer site when they experienced a peculiar problem with their Windows Server 2012 (WS2012) Hyper-V cluster. They were recovering a very large virtual machine. OK – nothing weird there. What was weird was that they lost management access to the hosts as soon as the restore job started. VMs were fine – it’s just that they couldn’t remotely manage their hosts any more.
I was told of the problem the following morning. It wasn’t in my project scope but I decided to dig around; I immediately suspected Redirected IO was to blame and that’s a topic I’ve written a word or two about in the past.
Recap: What is Redirected IO?
Redirected IO is a CSV feature where non-owners of the CSV will redirect their storage reads/writes to the storage via the owner of the CSV. In other words:
- The owner temporarily has exclusive read/write access to the CSV
- All other nodes in the cluster read/write from/to the CSV via the owner (or CSV coordinator)

Why is this done? There are two reasons in WS2012:
- There is a metadata operation taking place: this could be a VM start (very very quick), a dynamic virtual hard disk expansion, or even the creation of a fixed virtual hard disk.
- A node loses direct connectivity to the storage and uses redirect IO to avoid VM storage corruption or VM outage.
Note that redirected IO was used for Volume Shadow Copy Snapshot (VSS powered backup) operations in W2008 R2 but that is no longer the case in WS2012; it uses a new distributed snapshot mechanism to simply the backup.
Why Did Redirected IO Kick In Here?
Restoring the VM was a backup operation, right? No; it’s the complete opposite – it’s a restore operation and has absolutely nothing to do with VSS. Effectively the restore is creating files on a CSV … and that is one big mutha of a metadata operation. I wasn’t there at the time and I don’t know the backup tool, but I suspected that the admin restored the VM to a host that was not the owner of the target CSV. And that created tonnes of redirected IO:
- The backup application restored some 500 GB of VM to the destination node
- The node was not the CSV owner so redirected IO kicked in
- 500 GB of data went redirecting from the “restore” host to the CSV owner across 1 GbE networking and then into the storage
- Redirected IO finished up once the metadata operation (the restore) was completed
That’s my Dr. House theory anyway. I think I have it right – all the pieces fit. Of course, sometimes the patient died in House.
Didn’t They Control The Redirected IO Network?
They thought they did. The actually implemented the correct solution … for W2008 R2. That solution manipulates (if necessary) the network metric value to make the CSV network the one with the lowest metric. This is a WS2012 R2 cluster and things are different.
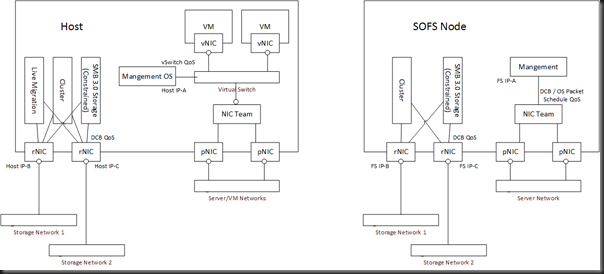
The clue why things are different is in the above illustration. There are two layers of redirected IO (the new lower block approach is 4 times faster) and bother are powered by SMB 3.0. What’s one of the new features of SMB 3.0? SMB Multichannel. And what does SMB Multichannel do? It finds every connection between the SMB client (the non-CSV owner) and the SMB server (the CSV owner) and uses all those networks to stream data as quickly as possible.
That’s great for getting the SMB transfer done as quickly as possible, but it can be damaging (as I suspected it was here) if left unmanaged. And that’s why we have features in WS2012 like QoS and SMB Constraints.
The Problem & Solution
In this case the hosts had a number of networks. The two that are relevant are the cluster network and the management network:
- Cluster network: A private network with 2 * 1 GbE NICs in a team
- Management network: 2 * 1 GbE in a team
Two networks and both were eligible for SMB 3.0 to use for SMB Multichannel during Redirected IO. And that’s what I suspect happened … 500 GB of data went streaming across both NIC teams for the duration of the restore operation. That flooded the management network. That made it impossible for administrators to remotely manage or RDP into the hosts in the cluster.
The solution in this case would be to use SMB constraints to control which networks would be used by SMB Multichannel at the client end. This cluster is simple enough in that regard. It uses iSCSI storage and SMB Multichannel should only be used by the team … so the team’s interfaces would be listed in the cmdlet. Now SMB Multichannel will only use the team.
I didn’t implement the solution – that is outside my scope on the project – but I’ve made the recommendation. I’ll update if I get any news.
In these types of clusters I’d recommend this solution as a part of the build process. It gets a bit more complicated if you’re using SMB 3.0 storage: just apply constraints to select any NIC that has a valid SMB Multichannel role, e.g. storage and redirected IO.