
In this post, I will share the details for granting the least-privilege permissions to GitHub action/DevOps pipeline service principals for a DevSecOps continuous deployment of Azure Firewall.
Quick Refresh
I wrote about the design of the solution and shared the code in my post, Enabling DevSecOps with Azure Firewall. There I explained how you could break out the code for the rules of a workload and manage that code in the repo for the workload. Realistically, you would also need to break out the gateway subnet route table user-defined route (legacy VNet-based hub) and the VNet peering connection. All the code for this is shared on GitHub – I did update the repo with some structure and with working DevOps pipelines.
This Update
There were two things I wanted to add to the design:
- Detailed permissions for the service principal used by the workload DevOps pipeline, limiting the scope of change that is possible in the hub.
- DevOps pipelines so I could test the above.
The Code
You’ll find 3 folders in the Bicep code now:
- hub: This deploys a (legacy) VNet-based hub with Azure Firewall.
- customRoles: 4 Azure custom roles are defined. This should be deployed after the hub.
- spoke1: This contains the code to deploy a skeleton VNet-based (spoke) workload with updates that are required in the hub to connect the VNet and route ingress on-prem traffic through the firewall.
DevOps Pipelines
The hub and spoke1 folders each contain a folder called .pipelines. There you will find a .yml file to create a DevOps pipeline.
The DevOps pipeline uses Azure CLI tasks to:
- Select the correct Azure subscription & create the resource group
- Deploy each .bicep file.
My design uses 1 sub for the hub and 1 sub for the workload. You are not glued to this bu you would need to make modifications to how you configure the service principal permissions (below).
To use the code:
- Create a repo in DevOps for (1 repo) hub and for (1 repo) spoke1 and copy in the required code.
- Create service principals in Azure AD.
- Grant the service principal for hub owner rights to the hub subscription.
- Grant the service principal for the spoke owner rights to the spoke subscription.
- Create ARM service connections in DevOps settings that use the service principals. Note that the names for these service connections are referred to by azureServiceConnection in the pipeline files.
- Update the variables in the pipeline files with subscription IDs.
- Create the pipelines using the .yml files in the repos.
Don’t do anything just yet!
Service Principal Permissions
The hub service principal is simple – grant it owner rights to the hub subscription (or resource group).
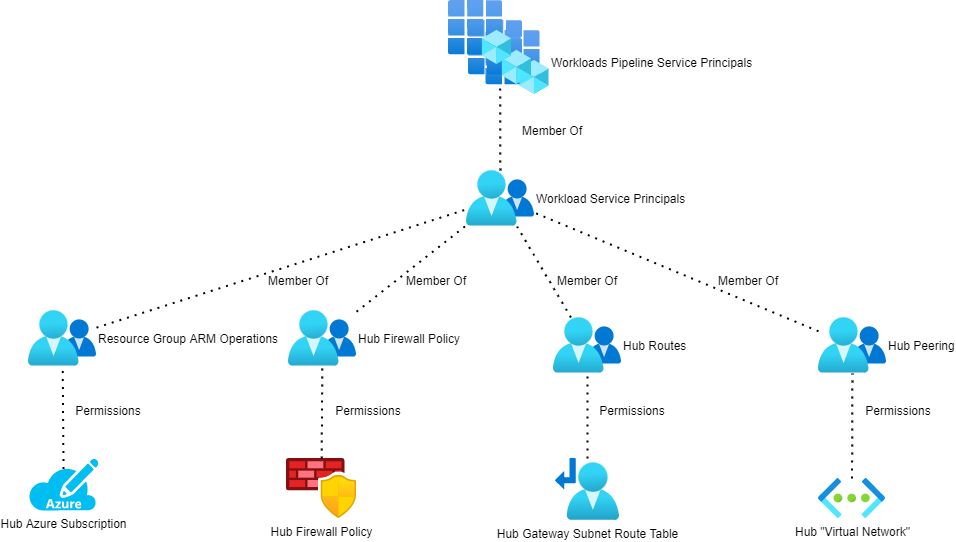
The workload is where the magic happens with this DevSecOps design. The workload updates the hub suing code in the workload repo that affects the workload:
- Ingress route from on-prem to the workload in the hub GatewaySubnet.
- The firewall rules for the workload in the hub Azure Firewall (policy) using a rules collection group.
- The VNet peering connection between the hub VNet and the workload VNet.
That could be deployed by the workload DevOps pipeline that is authenticated using the workload’s service principal. So that means the workload service principal must have rights over the hub.
The quick solution would be to grant contributor rights over the hub and say “we’ll manage what is done through code reviews”. However, a better practice is to limit what can be done as much as possible. That’s what I have done with the customRoles folder in my GitHub share.
Those custom roles should be modified to change the possible scope to the subscription ID (or even the resource group ID) of the hub deployment. There are 4 custom roles:
- customRole-ArmValidateActionOperator.json: Adds the CUSTOM – ARM Deployment Operator role, allowing the ARM deployment to be monitored and updated.
- customRole-PeeringAdmin.json: Adds the CUSTOM – Virtual Network Peering Administrator role, allowing a VNet peering connection to be created from the hub VNet.
- customRole-RoutesAdmin.json: Adds the CUSTOM – Azure Route Table Routes Administrator role, allowing a route to be added to the GatewaySubnet route table.
- customRole-RuleCollectionGroupsAdmin.json: Adds the CUSTOM – Azure Firewall Policy Rule Collection Group Administrator role, allowing a rules collection group to be added to an Azure Firewall Policy.
Deploy The Hub
The hub is deployed first – this is required to grant the permissions that are required by the workload’s service principal.
Grant Rights To Workload Service Principals
The service principals for all workloads will be added to an Azure AD group (Workloads Pipeline Service Principals in the above diagram). That group is nested into 4 other AAD security groups:
- Resource Group ARM Operations: This is granted the CUSTOM – ARM Deployment Operator role on the hub resource group.
- Hub Firewall Policy: This is granted the CUSTOM – Azure Firewall Policy Rule Collection Group Administrator role on the Azure Firewalll Policy that is associated with the hub Azure Firewall.
- Hub Routes: This is granted the CUSTOM – Azure Route Table Routes Administrator role on the GattewaySubnet route table.
- Hub Peering: This is granted the CUSTOM – Virtual Network Peering Administrator role on the hub virtual network.
Deploy The Workload
The workload now has the required permissions to deploy the workload and make modifications in the hub to connect the hub to the outside world.





