
I’m going to explain why the Cloud Adoption Framework can offer answers to Azure – even for organisations that have been in The Cloud for years.
Let Me Tell You Some Stories
As someone who started his professional career in IT back before Google was a thing, I have a few stories to tell.
The central IT department in a decentralised organisation spends months deploying an Azure infrastructure. Years later, they are puzzled as to why none of the other departments will use the cloud platform.
Another organisation spends a lot of money building a secure/flexible platform in Azure. 24 months later, the developers are still refusing to use this platform. They even seek out other ways to use Azure.
A very large organisation starts their cloud journey. A consultant asks them, “Have you done any preparation for the organisation?” The response is “We did that last week. Just get on with deploying stuff!”
These stories are based on truth. They are common stories – I know that anecdotally. Let’s figure out:
- What went wrong?
- How do we prevent it?
- What can you do if the above stories are similar to what you are experiencing?
Cloud Migration
Before big data, then IoT, and then AI, stole Microsoft’s focus, the corporation used to repeat this line:
Cloud is not where you work. Cloud is how you work.
Looking back on it, that oft-repeated marketing phrase genuinely had meaning, and it succinctly defines the problem.
Just about every (I’m being cautious, because I think it is every) cloud journey project that I was sent to work on as a consultant started this way:
- An IT manager ran the project.
- The reasoning was “get off of X, get out of Y” or some other technical reason that made sense to the IT manager.
- The project was contracted as (1) build the platform, (2) migrate the applications, and (3) do a handover to the IT department.
This is what I call a “cloud migration”. Why is that? The IT department is leaving a hosting facility, a computer room, old hardware, VMware/Nutanix/etc. They are lifting & shifting the VMs to Azure. Some new tooling will be used, but no processes will change.
The IT department will then tell the devs, “We are in the cloud! Come use the company-approved cloud.” The devs get some level of access and here’s their first experience when the business assigns a new project:
- They design the application without interaction with IT/IT Security, as usual.
- They attempt to deploy the application in Azure, but they have no rights.
- After a helpdesk ticket, some resource groups will be set up with assigned rights.
- The developers start to work, seek out some assistance, and are told that the design is unsuitable for compliance/security reasons. They must start over again.
- The new design requires some networking features. The developer has no rights to Azure networks, so this requires several helpdesk tickets to eventually resolve.
- Weeks later, the application is nowhere near ready. The business is impatient. The developer is frustrated.
This is not the story of one organisation. This has happened and is happening worldwide. The reason for this is that the IT department moved the applications to a new location. Nothing else changed.
Cloud Adoption
The cloud adoption journey is one of change. Typically sponsored by the business, A strategy is defined and clearly communicated:
- We are changing how we deliver IT services for the business
- Old organisational structures will be broken down to create a cooperative process. This will involve new tools and training before we put everything into action.
- A new method of working will empower on-demand self-service.
- Guardrails will be put in place to protect the organisation, its customers/suppliers/partners, and ensure operational excellence.
As you can see, there is a lot more going on here than “let’s use Veaam or Azure Migrate to shove some VMs into The Cloud.”
Some questions should arise now:
- Is there a canned process for doing this?
- How long is all this going to take?
- Is some 3-letter or 4-letter global consulting company going to be handing out ivory back scratchers as annual bonuses to their consultants at the end of this?

The Microsoft Azure Cloud Adoption Framework
The Microsoft Cloud Adoption Framework – let’s save my fingers and call it “the CAF” – was created and continues to be curated by Microsoft. The legend goes that Microsoft observed these issues and worked with Microsoft partners to create the CAF. The CAF contains a lot of information:
- How to build things in Azure
- How to operate Azure
- But most importantly, how to do the cloud adoption journey:
The CAF has evolved gradually since the first release, but the substance remains the same:
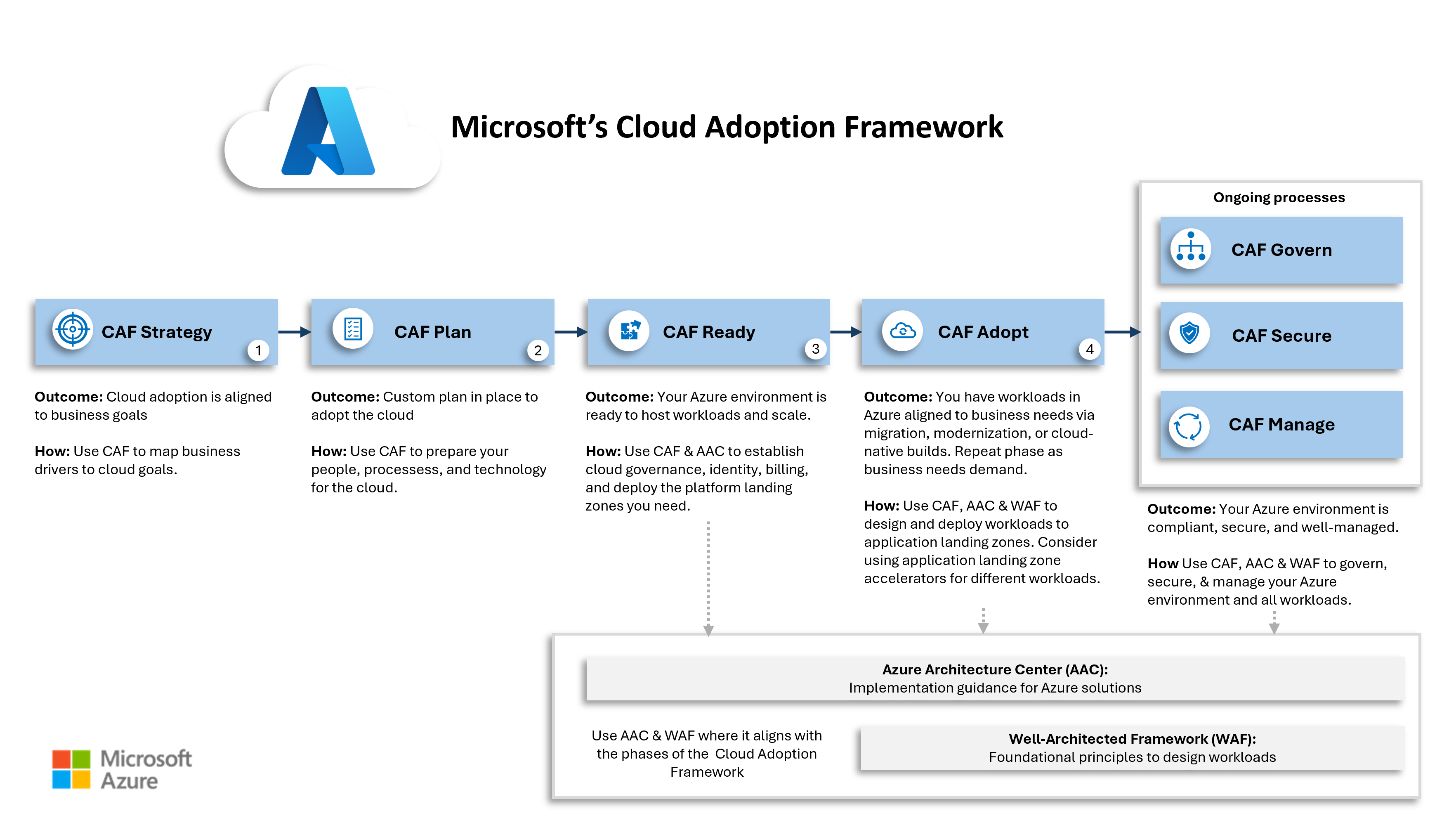
There are two methodologies:
- Core methodology: The core phases for a successful cloud adoption.
- Operational methodology: Building and continuously improving the guardrails.
In summary, the core methodology has 4 phases:
- Strategy: Understand why the organisation’s leadership wants to start the cloud adoption journey. Translate those motivations into measurable objectives and a mission statement. Write and clearly communicate a cloud strategy for the entire organisation.
- Plan: Any migration assessments (see objectives) will be started now because they will take time. However, the main work is defining the new IT operations model, preparing the organisational changes, identifying the required tools, and filling skills gaps through training/acquisition.
- Ready: The technical work begins! The tooling is readied. The first platform landing zones (shared infrastructure such as hubs) are built. The goal is to be ready for the first application landing zones.
- Adopt: The organisation finally gets the new/old applications in the cloud through migration, new builds, and innovation (this last one is quite important to business leaders).
The operational methodology will have three parallel tracks, starting after the cloud strategy is communicated, and aiming to have their minimal viable products available before Ready starts:
- Govern: Protections for the business are created, covering cost management/optimisation, compliance, and so on. This will be impacted, for technology reasons by Security and Manage.
- Secure: This is where modern IT security processes should be in action. A cloud security policy is created, dictating the technical security build, putting in the processes, and regularly doing risk assessments to improve the holistic posture.
- Manage: The more practical elements of running Azure are dealt with, including (but not limited to): disaster recovery, backup, patching, monitoring, alerting, and so on.
Each track will have a team with stakeholders (compliance officers, IT security, and so on) and technical staff that can architect and deploy the features. There will be a lot of crossover. For example, Azure Policy (seen as a governance product) can automate:
- Governance features
- Security audits/enforcements
- Operational excellence.
Aidan, what about the Well-Architected Framework (WAF)? Good question, if I do say so myself. The WAF contains several pillars that guide you to good design and good management. If you look at the pillars, it is easy to see that each can be owned by either Govern, Secure, or Manage.
Not Just For New Azure Customers
The CAF is not just for customers who are starting their Cloud adoption journey. As I’ve made clear, many organisations have embarked on a migration to Azure without making organisational/process/tools changes. They can’t ignore the resulting problems forever. It makes sense that those organisations take the time to figure out what changes to make. The CAF shows them the methodologies to make that happen.
Those same phases, tracks and steps can be applied to correct the course and make the necessary changes. I have started working with some clients on this very process.
Cloud Mechanix
I am a big fan of the Cloud Adoption Framework (CAF) but it is not perfect. The CAF has a process, but a lot of the content is “you could do this, you could do that” without practical opinion. With Cloud Mechanix, I deliver a streamlined and opinionated version of the CAF, focused on results. This delivery can be for new cloud adoption journeys and for those who are struggling to get their business to adopt an existing Azure environment. You can learn more about Cloud Mechanix here.





































