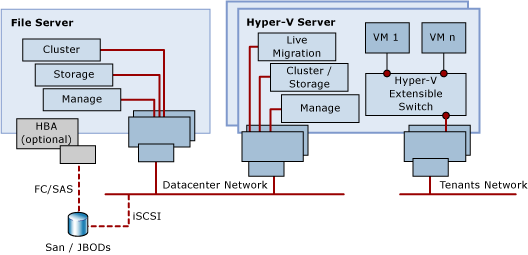
The new transparent failover, scalable, and continuously available active-active file server cluster, better known as Scale-Out File Server (SOFS) sounds really cool. Big, cheap disk, that can be bundled into a file server cluster that has higher uptime than everything that came before. It sure sounds like a cool way to provision file shares for end users.
And there’s the problem. As announced at Build in 2011, that is not what the Scale-Out File Server For Applicaion Data (to give it it’s full name) is intended for. Let’s figure out why; I always say if you understand how something works then you understand why/how to use something, and how/why not to use it.
The traditional active/passive clustered file server uses a shared-nothing disk that takes a few seconds to fail over from host to host. And it is active/passive. The SOFS is active-active. That means the file share, or the cluster resource, must be accessible on all nodes in the SOFS cluster. We need a disk that is clustered and available on all nodes at the same time. Does that sound familiar? It should if you read this blog: because that’s the same demand Hyper-V has. And in W2008 R2 we got Clustered Shared Volume (CSV), a clustered file system where one of the nodes orchestrates the files, folders, and access.
In CSV the CSV Coordinator, automatically handled by the cluster and made fault tolerant, handles all orchestration. Example of that orchestration are:
- Creating files
- Checking user permissions
To do this, nodes in the cluster go into redirected mode for the duration of that activity for the relevant CSV. In Hyper-V, we notice this during VSS backups in W2008 R2 (no longer present in WS2012 for VSS backup). IO is redirected from the SAS/iSCSI/FC connections to the storage, an sent over a cluster network via the CSV coordinator, which then proxies the IO to the SAN. This gives the CSV coordinator exclusive access to the volume to complete the action, e.g. create a new file, check file permissions.
This is a tiny deal for something like Hyper-V. We’re dealing with relatively few files, that are big. Changes include new VHD/VM deployments, and expansion of dynamic VHDs for VMs running non-coordinator nodes. SQL is getting support to store it’s files on SOFS, and it also has few, big files, just like Hyper-V. So no issue there.
Now think about your end user file shares. Lots and lots of teeny tiny little files, constantly being browsed in Windows Explorer, being opened, modified, and having permissions checks. Lots and lots of metadata activity. If these file shares were on an SOFS then it would probably be in near permanent SMB redirected IO mode (as opposed to block level redirected IO mode which was added in WS2012 for data stream redirection, e.g. caused by storage path failure).
We are told that continuously available file shares on a SOFS are:
- Good for file services with few, big files, with little metadata activity
- Bad for file services with many, small files, with lots of metadata activity
The official statement from Microsoft for the usage of SOFS can be found on TechNet:

In other words, DO NOT use the Scale-Out File Server solution for end user file shares. Do, and you will be burned.
[EDIT]
It’s been quite a while since I wrote this post, but people still are INCORRECTLY using SOFS as a file server for end users. They end up with problems, such as slow performance and this one. If you want to “use” a SOFS for file shares, then deploy a VM as a file server, and store that VM on the SOFS. Or deploy non-continuously available (legacy highly available) disks and shares on the SOFS for end users, but I prefer the virtual file server approach because it draws a line between fabric and services.
This makes perfect sense…You’d be better off using DFS and a replicated namespace if you want a highly available end user file share environment.
Do you happen to know of any changes to DFS in 2012?
Haven’t looked into it.
Ben, I don’t know about that strictly. SAN storage reliability is still greatly higher and servicing requirements greatly lower than the file servers themselves. So there’s definitely still a role for the conventional clustered file services where only one online copy of the data is justified.
If these shares are just hosting user/group files, the couple of seconds failover time usually isn’t a problem. Unfortunately, usually isn’t always – e.g. Explorer on clients seems to have a tendency to chuck a fit during the failover if it’s browsing the failed over share. Also I’ve seen applications that are constantly reading and don’t take kindly to any temporary IO error during the failover.
So it would have been nice if CSV would have been suitable for this role. Certainly not critical though.
That all said, does anybody actually like DFS Replication?!
I hate DFS. It is useless when you try open one file by multiple users. It is ok when, for example both users try to open file (.doc for example) on the same server. One of them will got the lock info.
But what happens when userA open a doc file on serverA and userB “the same file” on serverB? Both saves and where is my crystal ball to gues which file will be kept in DFS?
You do DFS and test it and understand that it is crap when multiple people modify files and you scramble into the Internet and come across a Microsoft article at last that says: “DFS is not recommended for scenarios where the same file is intended to be modified on two locations at the same time”. The end.
@Marcin: I guess you have a DFS Replication between those two servers right?
If yes then check this blog post http://blogs.technet.com/b/askds/archive/2010/01/05/understanding-dfsr-conflict-algorithms-and-doing-something-about-conflicts.aspx
Or else how do you sync the changes between them?