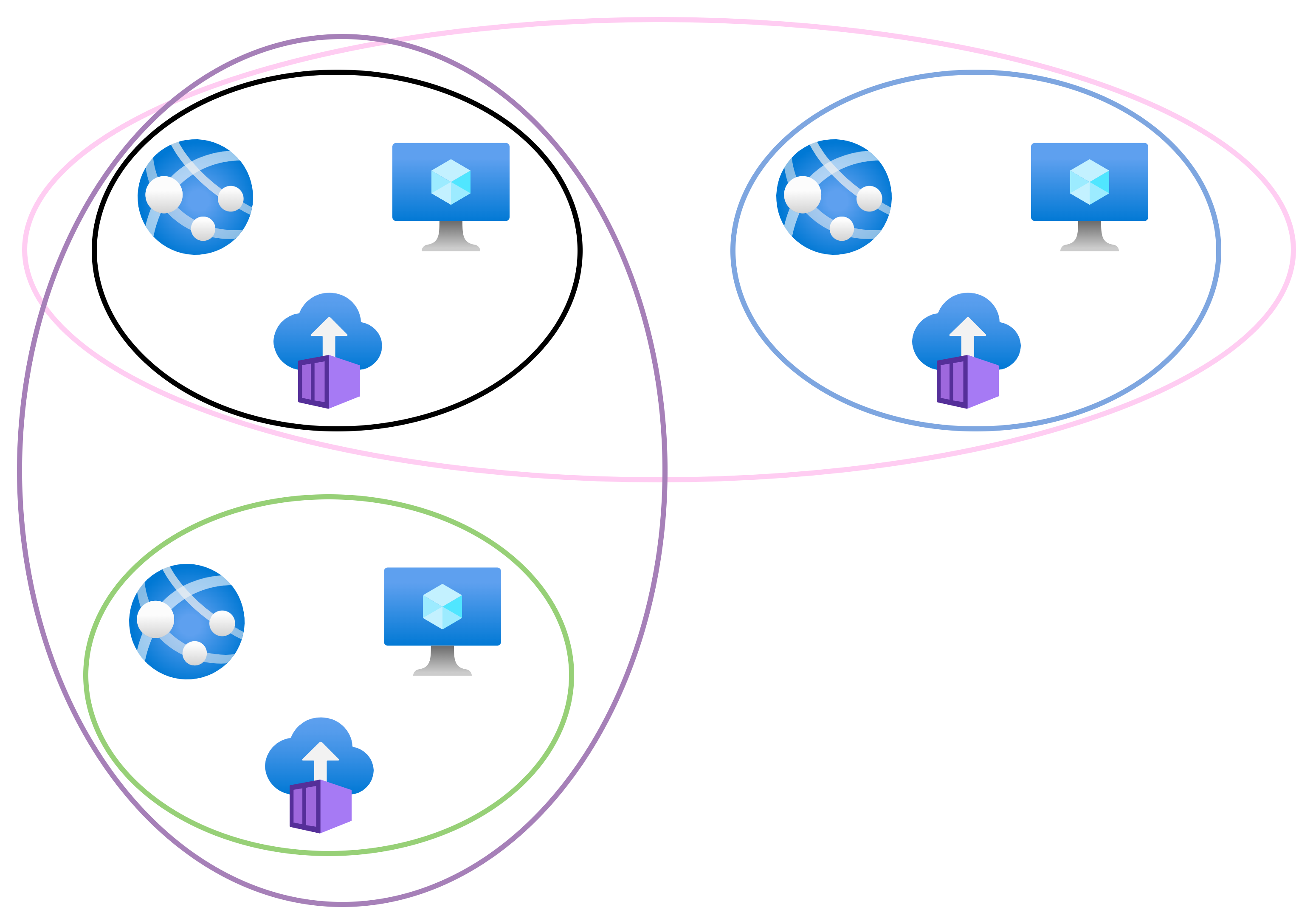
This is a topic that has been “top of mind” (I sound like a management consulting muppet) recently: how can I recover from an Azure region being destroyed?
Why Am I Thinking About This?
Data centres host critical services. If one of these data centres disappears then everything that was hosted in them is gone. The cause of the disaster might be a forest fire, a flood, or even a military attack – the latter was once considered part of a plot for a far-fetched airport novel but now we have to consider that it’s a real possibility, especially for countries close to now-proven enemies.
We have to accept that there is a genuine risk that an area that hosts several data centres could be destroyed, along with everything contained in those data centres.
Azure Resilience Features
Availability Sets
The first level of facility resilience in Microsoft’s global network (hosting all of their cloud/internal services) is the availability set concept; this is the default level of high availability designed to keep highly-available services online during a failure in a single fault domain (rack of computers) or deployment of changes/reboots to an update domain (virtual selection of computers) in a single row/room (rooms are referred to as colos). With everything in a single room/building we cannot consider an availability set to be a disaster resilience feature.
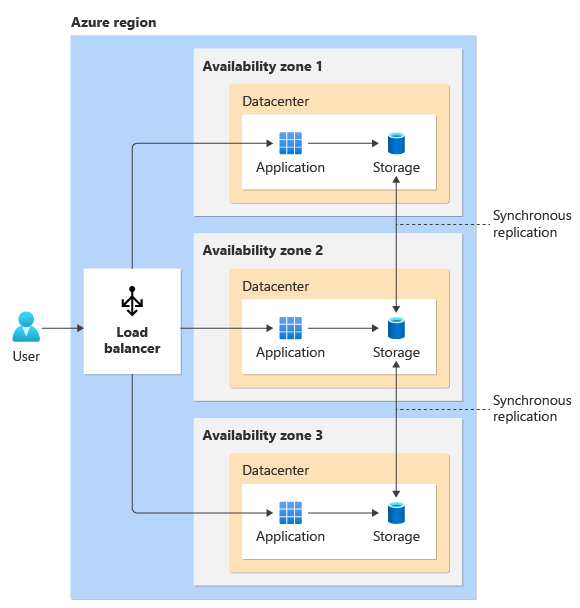
Availability Zones
The next step up is availability zones. Many Azure regions have multiple data centres. Those data centres are split into availability zones. Each availability zone has independent resources for networking, cooling and power. The theory is that if you spread a highly-available service across three zones, then if should remain operational if even two of the zones go down.
Paired Regions
An Azure region is a collection of data centres that are built close to each other (in terms of networking latency). For example, North Europe (Grangecastle, Dublin Ireland) has many physical buildings hosting Microsoft cloud services. Microsoft has applied to build more data centres in Newhall, Naas, Kildare, which is ~20 miles away but will only be a few milliseconds away on the Microsoft global network. Those new data centres will be used to expand North Europe – the existing site is full and more land would be prohibitively expensive.
Many Azure regions are deployed as pairs. Microsoft has special rules for picking the locations of those paired regions, including:
- They must be a minimum distance apart from each other
- They do not share risks of a common natural disaster
For example, North Europe in Dublin, Ireland is paired with West Europe in Middenmeer, Netherlands.
The pairing means that systems that have GRS-based storage are able to replicate to each other. The obvious example of that is a Storage Account. Less obvious examples are things like Recovery Services Vaults and some PaaS database systems that are built on Storage Account services such as blob or file.
Mythbusting
Microsoft Doesn’t Do Your Disaster Recovery By Default
Many people enter the cloud thinking that lots of things are done for them which are not. For example, when one deploys services in Azure, Azure does not replicate those things to the paired region for you unless:
- You opt-in/configure it
- You pay for it
That means if I put something in West US, I will need to configure and pay for replication somewhere else. If my resources use Virtual Networks, then I will need to have those Virtual Networks deployed in the other Azure Region for me.
The Paired Region Is Available To Me
In the case of hero regions, such as East US/West US or North Europe/West Europe, then the paired region is available to you. But in most cases that I have looked into, that is not the case with local regions.
Several regions do not have a paired region. And if you look at the list of paired regions, look for the * which denotes that the paired region is not available to you. For example:
- Germany North is not available to customers of Germany West Central
- Korea South is not available to users of Korea Central
- Australia Central 2 is not available to customers of Australia Central
- Norway West is not available to users of Norway East
The Norway case is a painful one. Many Norwegian organisations must comply with national laws that restrict the placement of data outside of Norwegian borders. This means that if they want to use Azure, they have to use Norway East. Most of those customers assume that Norway West will be available to them in the event of a disaster. Norway West is a restricted region; I am led to believe that:
- Norway West is available to just three important Microsoft customers (3 or 10, it’s irrelevant because it’s not generally available to all customers).
- It is hosted by a third-party company called Green Mountain near Stavanger, which is considerably smaller than an Azure region. This means that it will be small and offer a small subset of typical Azure services.
Let’s Burn Down A Region! (Hypothetically)
What’ll happen we this happens to an Azure region?

The Disaster
We can push the cause aside for one moment – there are many possible causes and the probability of each varies depending on the country that you are talking about. Certainly, I have discovered, both public and private organisations in some countries genuinely plan for some circumstances that one might consider a Tom Clancy fantasy.
I have heard Microsoft staff and heard of Microsoft staff telling people that we should use availability zones as our form of disaster recovery, not paired regions. What good will an availability zone do me if a missile, fire, flood, chemical disaster, or earthquake takes out my Azure region? Could it be that there might be other motivations for this advice?
Paired Region Failover
Let’s just say that I was using a region with an available pair. In the case of GRS-based services, we will have to wait for Microsoft to trigger a failover. I wonder how that will fare? Do you think that’s ever been tested? Will those storage systems ever have had the load that’s about to be placed on them?
As for your compute, you can forget it. You’re not going to start up/deploy your compute in the paired region. We all know that Azure is bursting at the seams. Everyone has seen quota limits of one kind of another restrict our deployments. The advice from Microsoft is to reserve your capacity – yes, you will need to pre-pay for the compute that you hope you will never need to use. That goes against the elastic and bottomless glass concepts we expect from The Cloud but reality bites – Azure is a business and Microsoft cannot afford to have oodles of compute sitting around “just in case”.
Non-Available Pair Failover
This scenario sucks! Let’s say that you are in Sweden Central or the new, not GA, region in Espoo, Finland. The region goes up in a cloud of dust & smoke, and now you need to get up and running elsewhere. The good news is that stateless compute is easy to bring online anywhere else – as long as there is capacity. But what about all that data? Your Data Lake is based on blob storage and couldn’t replicate anywhere. Your databases are based on blob/file storage and couldn’t replicate anywhere. Azure Backup is based on blob and you couldn’t enable cross-region restore. Unless you chose your storage very carefully, your data is gone along with the data centres.
Resource Groups
This one is fun! Let’s say I deploy some resources in Korea Central. Where will my resource group be? I will naturally pick Korea Central. Now let’s enable DR replication. Some Azure services will place the replica resources in the same resource group.
Now let’s assume that Korea Central is destroyed. My resources are hopefully up and running elsewhere. But have you realised that the resource IDs of those resources include the resource group that is in Korea Central (the destroyed region) then you will have some problems. According to Microsoft:
If a resource group’s region is temporarily unavailable, you might not be able to update resources in the resource group because the metadata is unavailable. The resources in other regions still function as expected, but you might not be able to update them. This condition might also apply to global resources like Azure DNS, Azure DNS Private Zones, Azure Traffic Manager, and Azure Front Door. You can view which types have their metadata managed by Azure Resource Manager in the list of types for the Azure Resource Graph resources table.
The same article mentions that you should pick an Azure region that is close to you to optimise metadata operations. I would say that if disaster recovery is important, maybe you should pick an Azure region that is independent of both your primary and secondary locations and likely to survive the same event that affects your primary region – if your resource types support it.
The Solution?
I don’t have one, but I’m thinking about it. Here are a few thoughts:
- Where possible, architect workloads where compute is stateless and easy to rebuild (from IaC).
- Make sure that your DevOps/GitHub/etc solutions will be available after a disaster if they are a part of your recovery strategy.
- Choose data storage types/SKUs/tiers (if you can) that offer replication that is independent of region pairing.
- Consider using IaaS for compute. IaaS, by the way, isn’t just simple Windows/Linux VMs. AKS is a form of very complicated IaaS. IaaS has the benefit of being independent of Azure, and can be restored elsewhere.
- Use a non-Microsoft backup solution. Veeam for example (thank you Didier Van Hoye, MVP) can restore to Azure, on-premises, AWS, or GCP.
What Do You Think?
I know that there are people in some parts of the world will think I’ve fallen off something and hit my head 🙂 I get that. But I also know, and it’s been confirmed by recent private discussions, that my musings here are already considered by some markets when adoption of The Cloud is raised as a possibility. Some organisations/countries are forced to think along these lines. Just imagine how silly folks in Ukraine would have felt if they’d deployed all their government and business systems in a local (hypothetical) Azure region without any disaster recovery planning; one of the first things to be at the wrong end of a missile would have been those data centres.
Please use the comments or social media and ping me your thoughts.